AI Model Fine-Tuning - 45 minutes
1. Goals of this lab
As Parasol Insurance embraces the era of AI, we face a unique challenge: leveraging cutting-edge AI technology while maintaining strict control over our proprietary data and processes. This journey requires us to develop in-house AI capabilities that are as powerful as they are secure. The goal of this lab is to show you as a developer how to use open source AI tooling to fine-tune a foundation model using Parasol’s proprietary data, producing an optimized and efficient LLM that can be used across a variety of use cases at Parasol. In this lab, you will:
-
Explore fine-tuning techniques for AI models, incorporating Parasol’s unique insurance expertise into LLMs
-
Learn how to create and utilize a custom knowledge base for training AI models with organization-specific scenarios and regulations
-
Apply the LAB methodology to generate synthetic training data and specialize our model while keeping data in-house
-
Gain hands-on experience in training and serving a customized AI model
-
Understand the benefits and limitations of fine-tuning compared to other AI customization methods
1.1. Enhancing AI Models: RAG vs Fine-Tuning
When customizing AI models, two techniques stand out: Retrieval-Augmented Generation (RAG) and fine-tuning.
-
Fine-tuning excels when you need precise, controlled outputs for specialized tasks using curated data. It’s ideal for applications where security and compliance require embedding all data within the model. Fine-tuning is also suitable when you have clear use cases with specific task requirements.
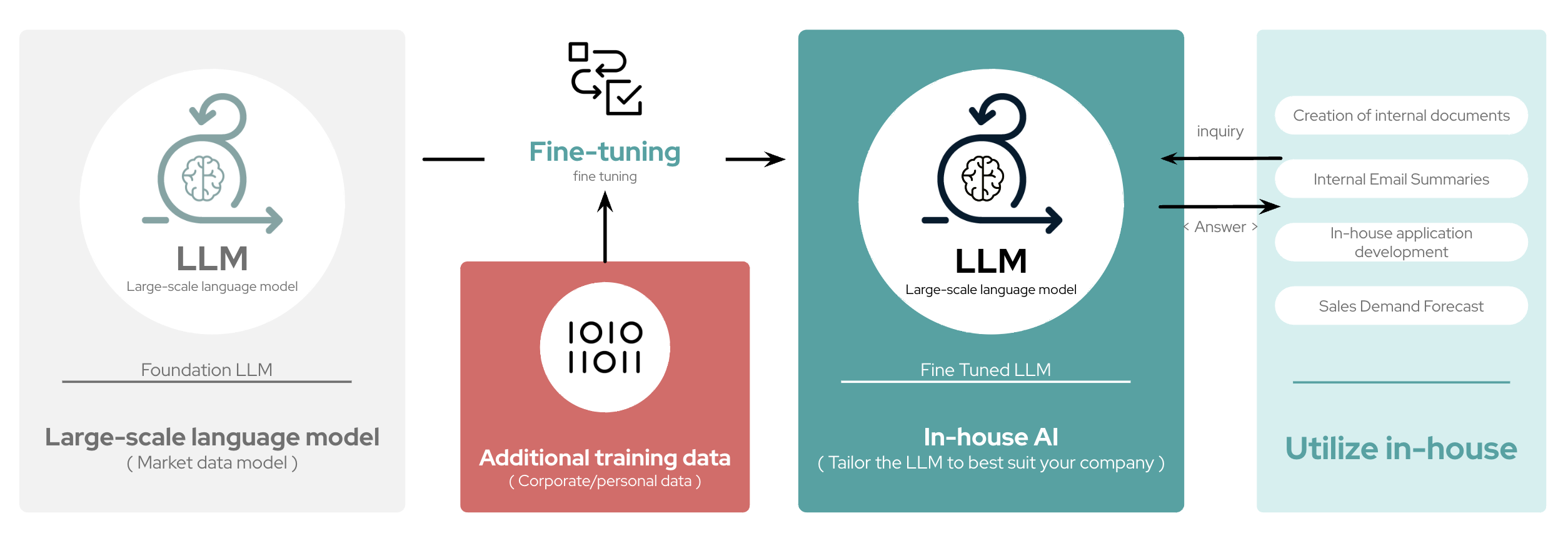
-
In contrast, Retrieval-Augmented Generation (RAG) is best when you need real-time access to dynamic knowledge bases, especially in environments with constantly updating information. RAG allows for scalability and handles out-of-domain queries effectively without the need for retraining, making it quick solution for improving model output. However, by providing contextual information to the model for each prompt, your expenses and computer resources may be higher than "baking-in" information into the model through fine-tuning.
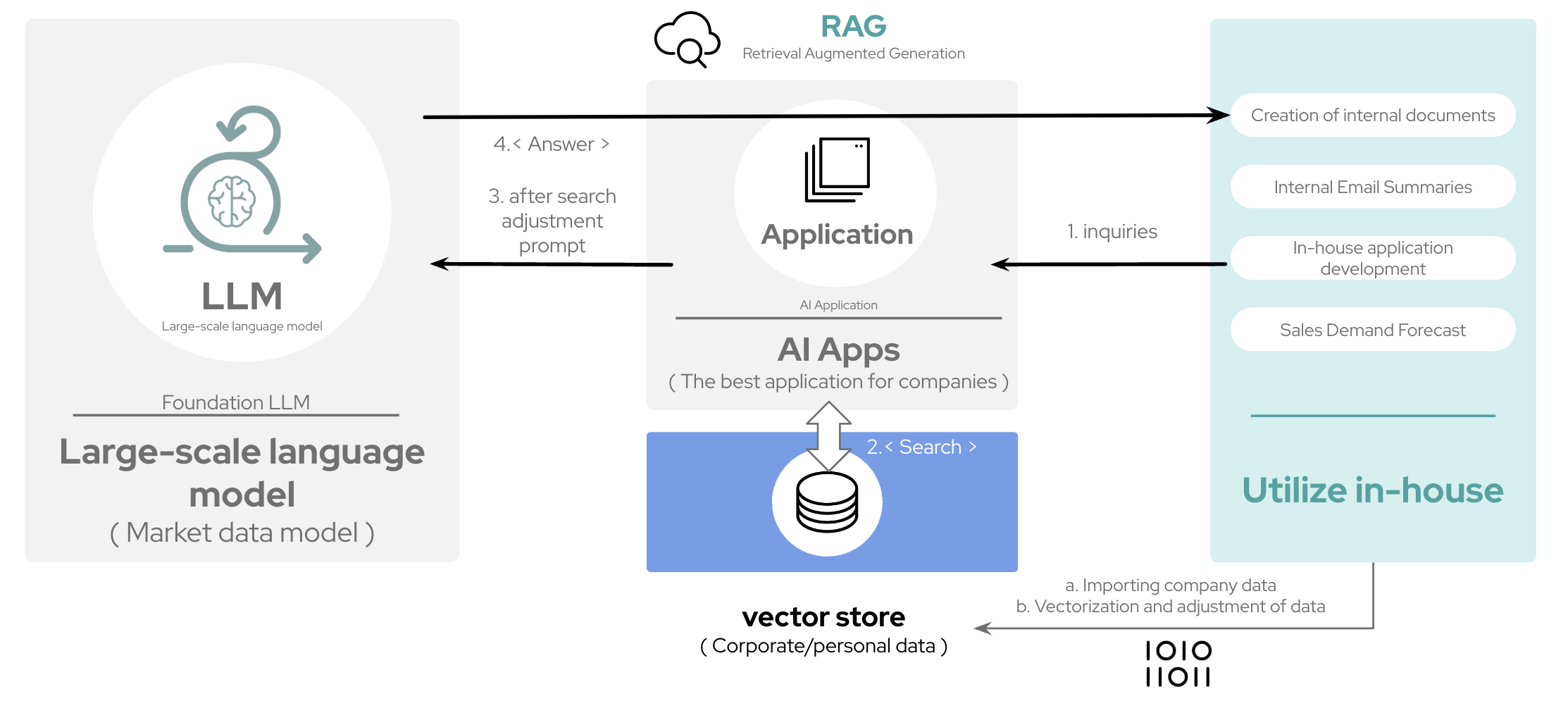
2. Get Started with Fine-Tuning
Now that we’ve outlined Parasol’s AI needs, let’s dive into the process of meeting them. In this section, we’ll explore how to use the InstructLab project to tailor a foundation language model to Parasol’s specific requirements, focusing on the key areas we’ve identified.
2.1. What is InstructLab?
InstructLab is an open-source project designed to enhance large language models (LLMs) for use in generative AI applications. It provides a novel approach to model alignment and fine-tuning, allowing developers and domain experts to add new knowledge and skills to pre-trained models with minimal data and computational resources. Key features of InstructLab include:
-
A taxonomy-driven approach to curating training data
-
Large-scale synthetic data generation
-
Iterative alignment tuning for continuous model improvement
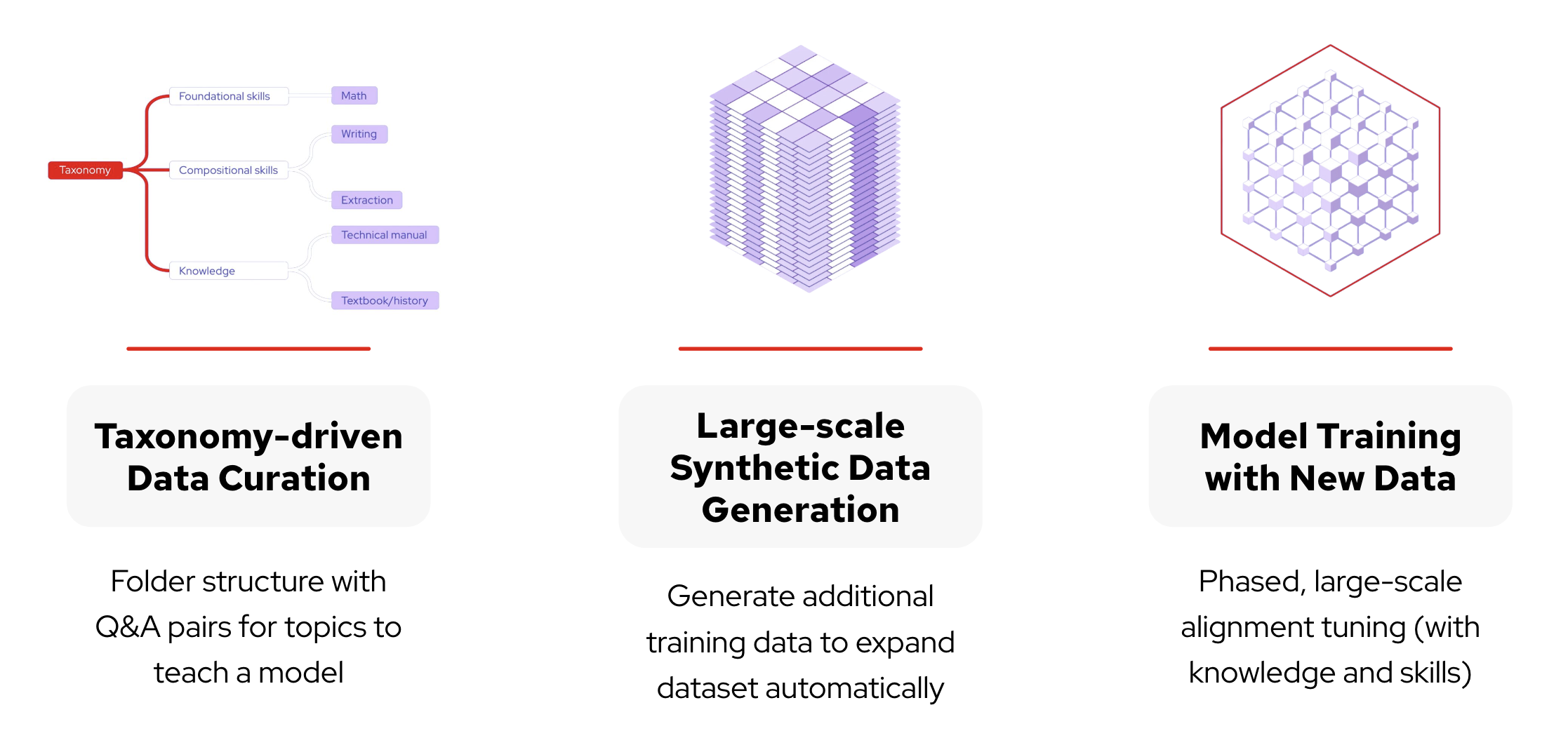
InstructLab is particularly useful for organizations that want to leverage private AI and keep their data in-house while still benefiting from state-of-the-art language models, without needing AI/ML or data science expertise.
As you work with InstructLab, you will see the terms Skills and Knowledge. What is the difference between Skills and Knowledge? A simple analogy is to think of a skill as teaching someone how to fish. Knowledge, on the other hand, is knowing that the best place to catch a Bass is when the sun is setting while casting your line near the trunk of a tree along the bank.
2.2. Access your Virtual Environment

2.2.4. Install Java 21
Run the following sdk command in the terminal.
sdk install java 21.0.5-temThe output should be similar to the following:
Downloading: java 21.0.5-tem
In progress...
######################################################################### 100.0%
Repackaging Java 21.0.5-tem...
Done repackaging...
Installing: java 21.0.5-tem
Done installing!
Setting java 21.0.5-tem as default.2.2.5. Build and run the Paasol Insurance application
Run the following bash script in the terminal.
sh parasol-insurance/scripts/run-parasol-app.shThis script will perform the following actions:
-
Build the Quarkus (parasol-insurance) application
-
Run the Quarkus application locally in the RHEL VM
It will take a few minutes to complete.
The output should end with the BUILD SUCCESS message.
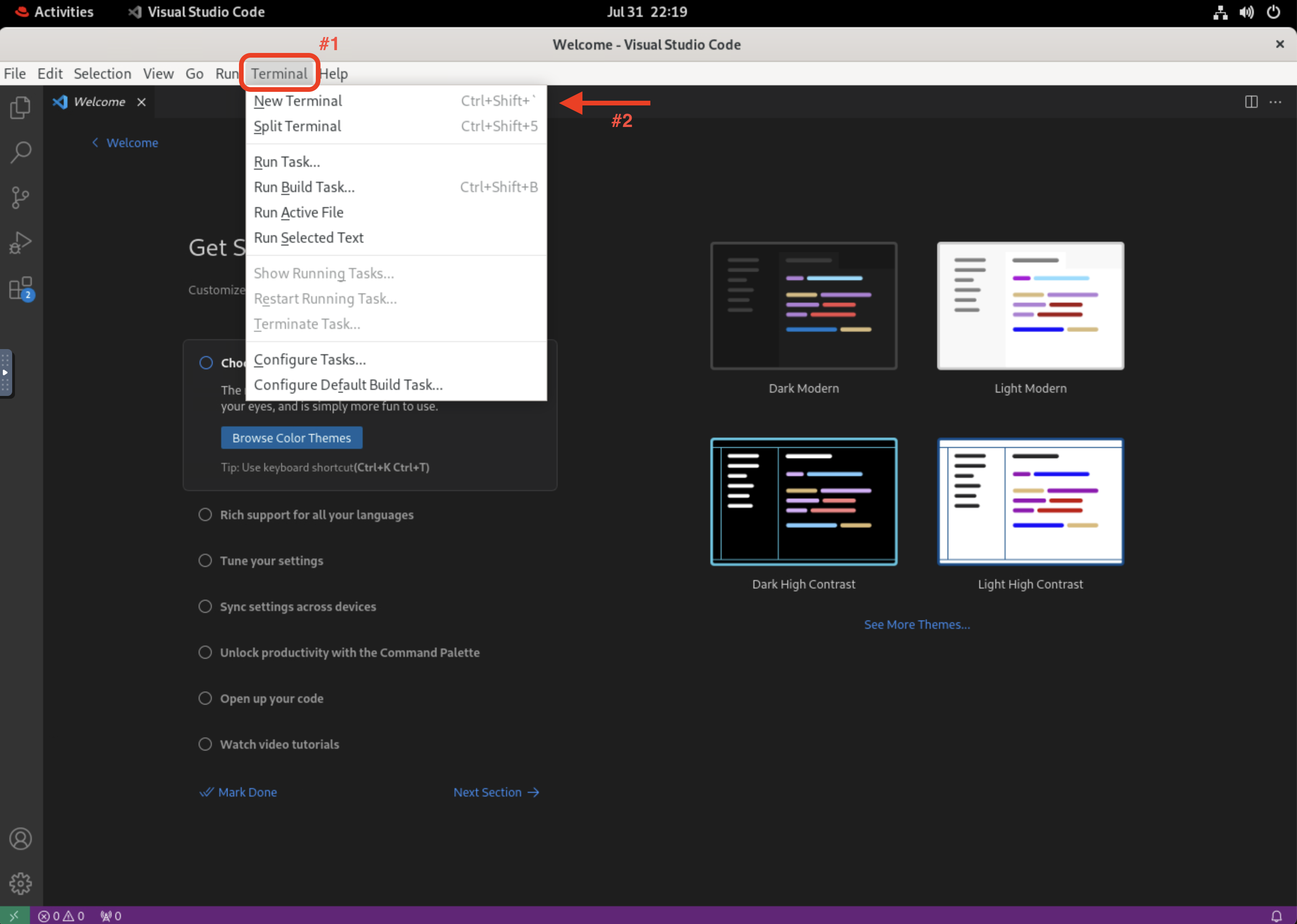
2.2.7. InstructLab mainly relies on the ilab command-line interface (CLI) to interact with the project
To access the ilab CLI, open a new terminal in Visual Studio Code by clicking on the Terminal menu and selecting New Terminal.
3. Model Fine-Tuning for the Insurance Organization
In the next few sections, we’ll walk through the process of fine-tuning an AI model using InstructLab. We’ll start by setting up our environment, generating synthetic training data, training the model, and then interacting with it. We will build upon that and delve further into the biggest insurance company in North America, Parasol, which has the most extensive customer base. Parasol Insurance gets many requests to process claims, questions about different products, etc. These requests are not just internal but also external.
Parasol Insurance’s primary concern is ensuring that its staff is capable of handling such requests and has access to this information through a single interface rather than going through multiple systems to scrape documents and internal portal pages. To this end, you have been tasked with adding knowledge that will aid the following use cases.
-
Products and coverage (e.g., providing comprehensive policy and product information)
-
Basic knowledge of the Insurance rules (e.g., offering insights on relevant local regulations)
-
Responses to general claim questions and remedies (e.g., generating product-specific email templates)
3.1. Preparing the Parasol Insurance Knowledge Base
The approach of fine-tuning a model allows us to shape a language model to better understand a specific domain, and fill in the gaps in its knowledge. The InstructLab taxonomy provides a structured way to guide the model fine-tuning process, enabling us to add domain-specific knowledge to the model in a heirarchical manner, similar to the example below:
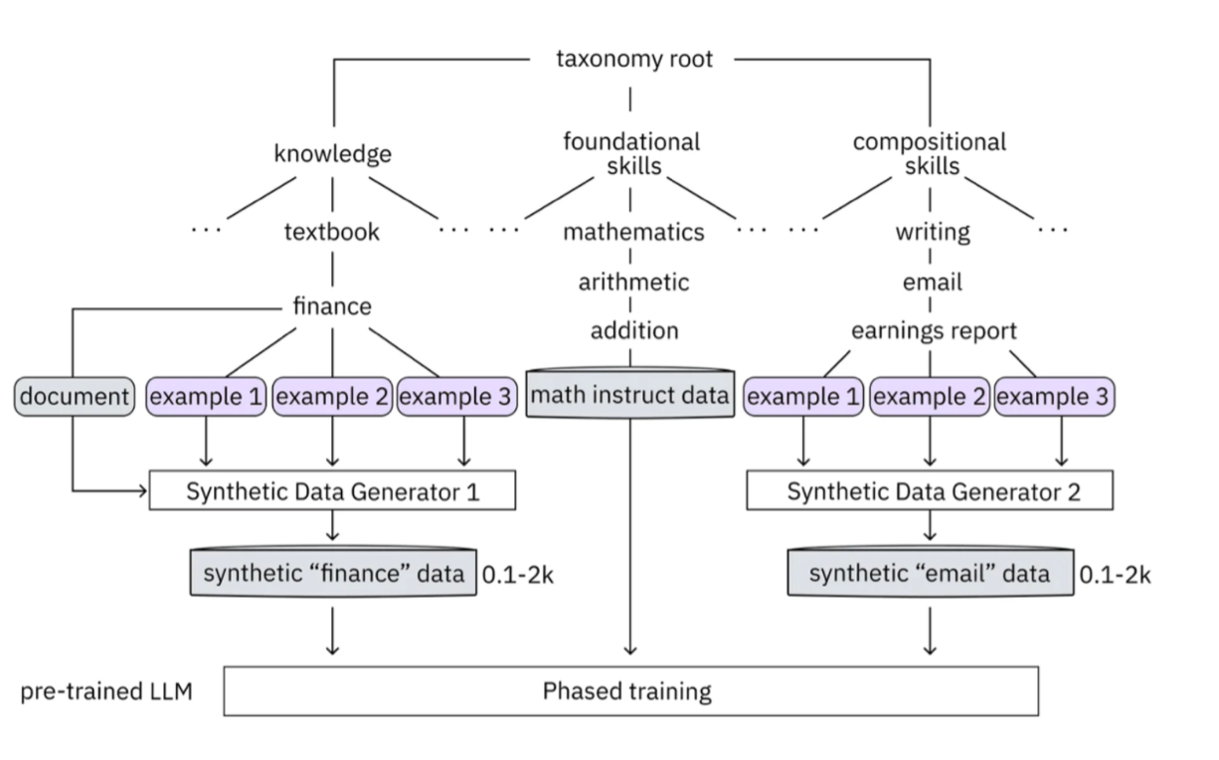
Your role is crucial in this process. You’ll be adding a knowledge domain to the LLM, using the organization’s specific information, knowledge that the LLM doesn’t have and is specific to Parasol Insurance.
3.2. Understanding the Knowledge Structure
Knowledge consists of data and facts and is backed by documents. When you create knowledge for a model, you’re giving it additional data to more accurately answer questions. Knowledge contributions in this project contain a few things:
-
A file in a Git repository that holds your information. For example, these repositories can include markdown versions of information on: Parasol products, insurance domain knowledge, claims processing etc.
-
A
qna.yamlfile that asks and answers questions about the information in the git repository, with desirable responses. -
An
attribution.txtthat includes the sources for the information used in theqna.yaml, which aids in transparency and accountability.
LLMs have inherent limitations that make certain tasks extremely difficult, like doing math problems. They’re great at other tasks, like creative writing. And they could be better at things like logical reasoning. However, these limitations can be overcome by providing them with the right knowledge (and skills, which InstructLab can also help with). An LLM with knowledge helps it create a basis of information that it can learn from, then you can teach it to use this knowledge via the qna.yaml files.
In our case we want the LLM to learn more about Parasol Insurance by supplying this specific information in the form of a basic YAML file named qna.yaml:
version: 3(1)
domain: insurance(2)
created_by: sshaaf(3)
seed_examples:(4)
- context: |(5)
In the insurance industry, accurately predicting the likelihood of claims is
essential for risk assessment and policy pricing. However, Parasol insurance
claims datasets frequently suffer from class imbalance, where the number of
non-claims instances far exceeds that of actual claims.
questions_and_answers:
- question: What is class imbalance in the context of Parasol insurance claims datasets?
answer: |
Class imbalance refers to the situation where the number of non-claims
instances far exceeds that of actual claims, making predictive modeling
difficult and potentially leading to biased models.
- question: What types of information are included in the Policyholder Information feature?
answer: |
Policyholder Information includes demographic details like age, gender,
occupation, marital status, and geographical location, which are critical
for assessing risk.
# more questions and answers
document_outline: |(6)
Information about the Parasol insurance claims data glossary, terms and how
to read and understand claims. The information is related to the Parasol
insurance internal records and systems.
document:(7)
repo: https://github.com/rh-rad-ai-roadshow/parasol_knowledge.git
commit: 07227df21a3a786d15ae5b88ece2c33bd78ee36a
patterns:(8)
- Parasol_auto_insurance.md
- Insurance_claims_data.md
- teen_driving_rules.md
- claims_cost_data.mdEach qna.yaml file requires a minimum of five question-answer pairs. The qna.yaml format must include the following fields:
| 1 | version: Defines the InstructLab taxonomy schema version |
| 2 | domain: Category of the knowledge |
| 3 | created_by: The author of the contribution, typically a GitHub username |
| 4 | seed_examples: Five or more examples sourced from the provided knowledge documents, representing a question for the model and desired response |
| 5 | context: A chunk of information from the knowledge document. |
| 6 | document_outline: An outline of the document containing the knowledge you’re adding to the model. |
| 7 | document: The source of your knowledge contribution, consisting of a repo URL pointing to the knowledge markdown files, and commit identifier for the specific commit that contains the files |
| 8 | patterns: A list of glob patterns specifying the markdown files in your repository that should be used during training. We have placed all the knowledge documents in the parasol-knowledge repository. |
3.3. Creating the Parasol Insurance Knowledge Base
Now that we understand the constructs of the taxonomy’s knowledge, let’s go ahead and create our knowledge base, which we will then feed into the LLM to train. This will help our applications that utilize the LLM, and agents directly chatting with the model. Furthermore, it will help with claims processing, fraud detection, or anyone who would like to ask the LLM about products, coverage, laws, and some information about Parasol itself. Let’s get started!
3.3.1. Open the instructlab taxonomy directory in Visual Studio Code
Open VSCode by running the below command. Even if you already have VSCode open, you should run this command to open the taxonomy folder (notice the --reuse-window flag).
code ~/.local/share/instructlab/taxonomy --reuse-windowIf you are prompted to create a new keyring passcode, simply enter any password here (you won’t need this again):
3.3.3. Navigate to the knowledge/ folder
This file will contain the questions and answers that will be used to train the model.
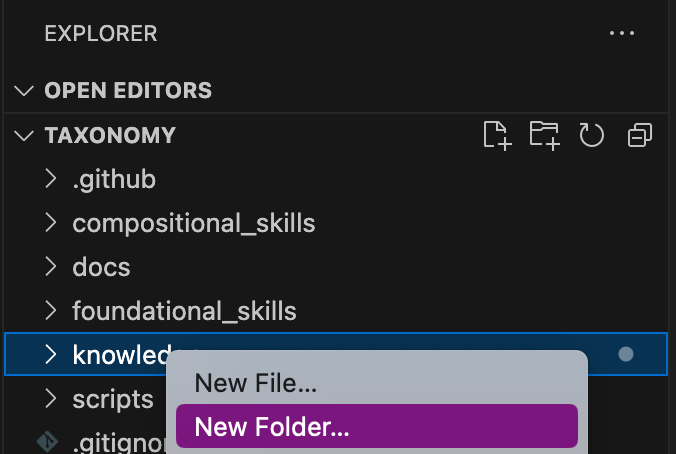
3.3.4. Create a structure for Parasol insurance knowledge
To do that create folders by first right clicking on the Knowledge folder, and then pressing New Folder, as shown in the screen shot below
We should create a knowledge folder structure that we can add to later as we add more knowledge and for our peers to also understand how its structured. Lets create a structure like this knowledge > economy > finance > insurance > parasol. In VSCode this is quite easy.
4. Curating the Data for our AI Model
Let’s now add the following taxonomy knowledge file for Parasol Insurance. Each section of this file addresses different aspects of Parasol’s insurance policies:
-
Like any insurance company on the planet, data is stored into multiple systems, files etc. Employees at Parasol Insurance either using the system for the first time or using it for e.g. detecting fraud, trying to understand the glossary, acronyms etc. A good example is
Policy ID, a unique ID for policy in our database systems. The LLM does not know about this. By adding this, we can ensure that once a claims agent or an application asks about a policy ID, the LLM can give reasonable answers and suggestions. -
Information about the Parasol Insurance company, and an overview of product details. This will enable the LLM to give answers on a high level about the different offerings, formulate a context about Parasol Insurance, its history, etc.
-
Information specific to policies in relation to the different products. This will help our claims processing agents to ask questions about specific cases and scenarios to the LLM. The LLM should be able to suggest remedies or further knowledge to look into.
The questions covered in the questions & answered should be answerable through the knowledge document(s) defined at the end of this file.
4.1. Create knowledge file
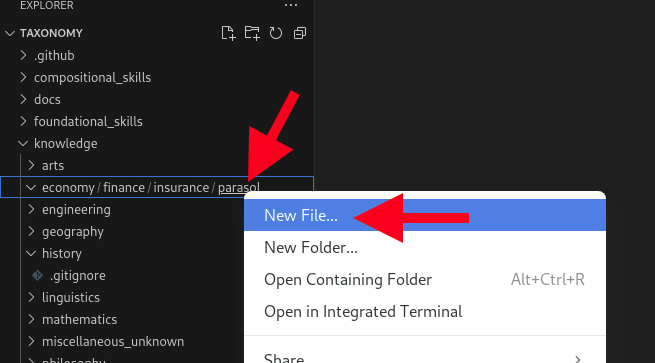
Copy the following and add it as a new file called qna.yaml in the folder parasol as shown in the image above. "qna" is short for "questions and answers". To do this, right-click on parasol folder name and select New File…:
Enter the filename qna.yaml to create the file. Then, copy in the following content into the file (using the special copy/paste procedure as before):
version: 3
domain: insurance
created_by: sshaaf
seed_examples:
- context: |
In the insurance industry, accurately predicting the likelihood of claims is essential for risk assessment and
policy pricing. However, Parasol insurance claims datasets frequently suffer from class imbalance, where the
number of non-claims instances far exceeds that of actual claims. This class imbalance poses challenges for
predictive modeling, often leading to biased models favoring the majority class, resulting in subpar performance
for the minority class, which is typically of greater interest.
questions_and_answers:
- question: What is class imbalance in the context of Parasol insurance claims datasets?
answer: |
Class imbalance refers to the situation where the number of non-claims instances far exceeds that of actual
claims, making predictive modeling difficult and potentially leading to biased models.
- question: What types of information are included in the Policyholder Information feature?
answer: |
Policyholder Information includes demographic details like age, gender, occupation, marital status, and
geographical location, which are critical for assessing risk.
- question: What kind of data is contained in the Claim History feature?
answer: |
The Claim History feature contains past insurance claims data, including claim amounts, claim types,
frequency, and duration, essential for evaluating a policyholder's risk.
- question: What details are provided under the Policy Details feature?
answer: |
Policy Details encompass information about the insurance policies, such as coverage type, policy duration,
premium amounts, and deductibles, which help in determining policy pricing.
- question: What are Risk Factors in the context of Parasol Insurance Claims data?
answer: |
Risk Factors include variables like credit score, driving record, and health status, which indicate the
potential risks associated with a policyholder and are crucial for risk assessment.
- context: |
Parasol Insurance’s policies related to car rental coverage, loss of income
insurance, and the Apex Plus package. It explains when and how the company covers daily rental charges, the
requirements for receiving payments, and the additional benefits provided by the Apex Plus package.
questions_and_answers:
- question: What is the car rental policy from Parasol Insurance?
answer: |
Parasol Insurance covers the daily rental charge when an insured vehicle is undriveable or being repaired due
to a loss covered under comprehensive insurance. The coverage begins on the date the vehicle becomes
undriveable and ends when the vehicle is repaired, replaced, or seven days after the loss is settled if the
vehicle is stolen and not recovered. The rental amount must be reported to Parasol Insurance before they will
make any payments.
- question: When will Parasol Insurance pay daily rental charge incurred?
answer: |
Parasol Insurance pays the daily rental charge when an insured rents a car while their vehicle is undriveable
or being repaired due to a loss covered under comprehensive coverage.
- question: When will Parasol Insurance start paying daily car rental charges?
answer: |
Parasol Insurance starts covering daily rental charges from the date the vehicle is undriveable or when it is
left at a repair facility, provided the loss is covered under the policy.
- question: When will payments for Car Insurance from Parasol Insurance end?
answer: |
Payments for car rental end when the vehicle is repaired, replaced, or seven days after Parasol offers to pay
for the loss if the vehicle is stolen and not recovered.
- question: What is the Parasol insurance Apex plus package?
answer: |
The Apex Plus package offers additional coverage, including loss of income insurance and uninsured driver
insurance, enhancing the standard policy coverage.
- context: |
Parasol Insurance is a well-known company founded in 1936 by James Falkner and James Labocki Sr. It originally
targeted federal government employees and enlisted military officers. In 2024, Parasol was acquired by Joe
Fernandes, who is the head of InstructLab. The company offers a variety of insurance products including auto,
homeowners, renters, boat, RV, identity theft protection, and life insurance. They are known for their competitive
discounts and strong financial ratings. The Apex Plus package provides additional coverage options, including loss
of income and uninsured motorist coverage.
questions_and_answers:
- question: When was Parasol Insurance founded and by whom?
answer: |
Parasol Insurance was founded in 1936 by James Falkner, James Labocki Sr., and a group of investors from
around the world.
- question: What was Parasol Insurance's original target market?
answer: |
Parasol Insurance originally targeted federal government employees and certain categories of enlisted military
officers.
- question: Who acquired Parasol Insurance in 2024 and what is his role?
answer: |
Joe Fernandes acquired Parasol Insurance in 2024 and is the head of InstructLab, which is the parent company
of Parasol.
- question: What are the main products and services offered by Parasol Insurance?
answer: |
Parasol Insurance offers auto insurance, homeowners insurance, renters insurance, boat insurance, RV
insurance, identity theft protection, life insurance, business insurance, and various other coverages through
partnerships with other insurance companies.
- question: What are some of the discounts offered by Parasol Insurance?
answer: |
Parasol Insurance offers discounts such as multi-policy, good driver, military, federal employee, and student
discounts.
- context: |
In Alaska, drivers must be at least 14 years old to obtain an instruction permit. Teens must hold a learner's
permit for at least six months and complete 40 hours of supervised driving (including 10 hours at night or in
inclement weather) before they can apply for a license. Until a teen driver turns 18, he or she will get a
provisional license, which prohibits the driver from riding with passengers under the age of 21 and from being on
the road between 1:00 AM and 5:00 AM. Teens may drive during those hours if a driver older than 21 is in the car
with them. Restrictions are lifted at age 18. Teenage drivers in New Hampshire are allowed to practice driving
beginning at age 15 ½ while accompanied by a licensed adult at least 25 years of age in the front passenger seat.
All unlicensed drivers must carry identification that shows proof of age.
questions_and_answers:
- question: What is the minimum age to obtain an instruction permit in Alaska?
answer: |
In Alaska, drivers must be at least 14 years old to obtain an instruction permit.
- question: How many hours of supervised driving are required in Alaska before a teen can apply for a license?
answer: |
Teens in Alaska must complete 40 hours of supervised driving, including 10 hours at night or in inclement
weather, before they can apply for a license.
- question: What restrictions are placed on provisional license holders under 18 in Alaska?
answer: |
Provisional license holders under 18 in Alaska are prohibited from riding with passengers under the age of 21
and from driving between 1:00 AM and 5:00 AM, unless accompanied by a driver older than 21.
- question: At what age are driving restrictions lifted for teen drivers in Alaska?
answer: |
Driving restrictions for teen drivers in Alaska are lifted at age 18.
- question: What is the minimum age for a teen to practice driving in New Hampshire?
answer: |
Teen drivers in New Hampshire can begin practicing driving at age 15 ½ while accompanied by a licensed adult
at least 25 years of age.
- question: What are the requirements for obtaining a New Hampshire Youth Operator License?
answer: |
To obtain a New Hampshire Youth Operator License, teens must be at least 16 years old, pass a state-approved
driver education course, provide written permission from a parent or guardian, log at least 40 hours of
supervised driving practice (including 10 hours of nighttime driving), and pass a vision screening, a written
test, and a driver road test.
- question: What are the driving restrictions for Youth Operator License holders under 18 in New Hampshire?
answer: |
Youth Operator License holders under 18 in New Hampshire are prohibited from driving between 1:00 AM and 4:00
AM and may not drive with more than one passenger younger than age 25 who is not a family member during the
first 6 months of being licensed, unless accompanied by a licensed driver at least 25 years old.
- question: How much is the application fee for a New Hampshire Youth Operator License?
answer: |
The application fee for a New Hampshire Youth Operator License is $50.
- question: How is the New Hampshire Youth Operator License oriented, and what special marking does it have?
answer: |
The New Hampshire Youth Operator License is oriented vertically and states: "Under 21 until [date]". It
expires on the individual's 21st birthday.
- question: |
When can a New Hampshire Youth Operator License holder obtain a horizontally-oriented driver's
license?
answer: |
A New Hampshire Youth Operator License holder can obtain a horizontally-oriented driver's license on their
21st birthday.
- context: |
Provides an overview of the key features and elements within Parasol Insurance's claims datasets. It
covers topics such as class imbalance, which poses challenges for predictive modeling due to the disproportionate
number of non-claims versus claims instances. It also details the types of information included in the
dataset, such as policyholder demographics, claim history, policy specifics, risk factors, and external
influences. These features are critical for various insurance-related applications, including risk assessment,
policy pricing, fraud detection, and customer segmentation. Understanding these components is essential for
leveraging the data effectively in predictive models and decision-making processes within the insurance domain.
questions_and_answers:
- question: How can the data be used for Fraud Detection?
answer: |
The data can be used to identify fraudulent insurance claims by detecting anomalous patterns in claim
submissions and policyholder behavior.
- question: What is Customer Segmentation in the context of Parasol Insurance Claims data?
answer: |
Customer Segmentation involves segmenting policyholders into distinct groups based on their risk profiles and
insurance needs to tailor marketing strategies and policy offerings.
- question: What does the term 'policy id' refer to in the dataset?
answer: |
'Policy id' is a unique identifier for the insurance policy.
- question: How does the 'customer age' feature influence insurance claims?
answer: |
'Customer age' refers to the age of the policyholder, which can influence the likelihood of claims.
- question: What impact does 'vehicle age' have on claim probability?
answer: |
'Vehicle age' affects the probability of claims due to factors like wear and tear.
- question: Why is the 'model' of the vehicle included in the dataset?
answer: |
The 'model' of the vehicle could impact the claim frequency due to model-specific characteristics.
- question: How does the 'fuel type' of a vehicle influence the risk profile?
answer: |
'Fuel type' (e.g., Petrol, Diesel, CNG) might influence the risk profile and claim likelihood of the vehicle.
- question: What do 'max torque' and 'max power' describe in the dataset?
answer: |
'Max torque' and 'max power' describe the engine performance characteristics, which could relate to the
vehicle’s mechanical condition and claim risks.
- question: What does the 'engine type' feature indicate?
answer: |
'Engine type' indicates the type of engine, which might have implications for maintenance and claim rates.
- question: Why is 'region code' important in the insurance claims data?
answer: |
'Region code' represents the geographical region of the policyholder, as claim patterns can vary regionally.
- question: What does 'region density' show, and why is it relevant?
answer: |
'Region density' shows the population density of the policyholder’s region, which could correlate with
accident and claim frequencies.
- question: How does the number of 'airbags' in a vehicle influence claim probability?
answer: |
The number of 'airbags' in a vehicle indicates its safety level, which can influence the probability of
claims.
- question: What does the 'claim status' feature indicate in the dataset?
answer: |
'Claim status' indicates whether a claim was made (1) or not (0), and is the dependent variable the model aims
to predict.
document_outline: |
Information about the Parasol insruance claims data glossary, terms and how to read and understand claims.
The information is related to the Parasol insurance internal records and systems.
document:
repo: https://github.com/rh-rad-ai-roadshow/parasol_knowledge.git
commit: 07227df21a3a786d15ae5b88ece2c33bd78ee36a
patterns:
- Parasol_auto_insurance.md
- Insurance_claims_data.md
- teen_driving_rules.md
- claims_cost_data.mdAnd now lets also create an attribution.txt file for citing sources. Copy the following and create a new file attribution.txt in the same folder parasol:
Title of work: Parasol Insurance
Link to work: https://huggingface.co/rh-rad-ai-roadshow
License of the work: CC-BY-SA-4.0
Creator names: Syed M Shaaf, Philip Hayes4.2. Check that the Taxonomy is Recognized by InstructLab
Now that we’ve added data, let’s check that the taxonomy is recognized by InstructLab. This will help us ensure that the data we’ve added is valid and can be used to generate synthetic training data.
We’re going to run some commands from the terminal, so from the Terminal menu, select New Terminal to open a new terminal window (or use the terminal you already have open).
Let’s navigate to the instructlab directory:
cd ~/instructlabNow, activate the Python virtual environment:
source venv/bin/activateRun the following command to check the validity of the taxonomy:
ilab taxonomy diffAfter running the above command you should be able to see the following output.
knowledge/economy/finance/insurance/parasol/qna.yaml
Taxonomy in /home/instruct/.local/share/instructlab/taxonomy is valid :)
If you see an error such as no new line character at the end of the file, simply place your cursor at the end of the last line of the taxonomy file and press ENTER to add a new line, and re-run the ilab diff command.
|
If you do not see output similar to above, you may not have added in all of the Q&A file. This is important as the model will use this file to generate synthetic data in the next section.
5. Generating Synthetic Training Data & Training the New Model
Now that we’ve added some initial data, let’s use InstructLab to generate synthetic training data. Large Language Models inherently require a large amount of data to be effective, and it can be difficult to find enough real-world data for a niche domain. However, by using InstructLab, we can generate synthetic data that can be used to train the model.
5.4. Run the data generation command:
ilab data generate --model ~/instructlab/models/granite-7b-lab-Q4_K_M.gguf --sdg-scale-factor 1 --enable-serving-outputTo reduce the amount of time the generation process takes, we are setting the "--sdg-scale-factor" to 1 (The number of instructions to generate for each seed
example), the default for this value is 30. If we were generating data for a production deployment we would likely set this value higher.
This process may take some time (up to 3 minutes for this lab), depending on the amount of data and the computational resources available. Feel free to wait, or stop the process with CTRL+C as we will not be using these files in the next step in the interest of time. You may also want to open a separate Terminal and run the nvtop command to see the use of your GPU during this generation phase. Click the + button and run nvtop in the new terminal (you may need to make the terminal window bigger to see the moving line graphs):
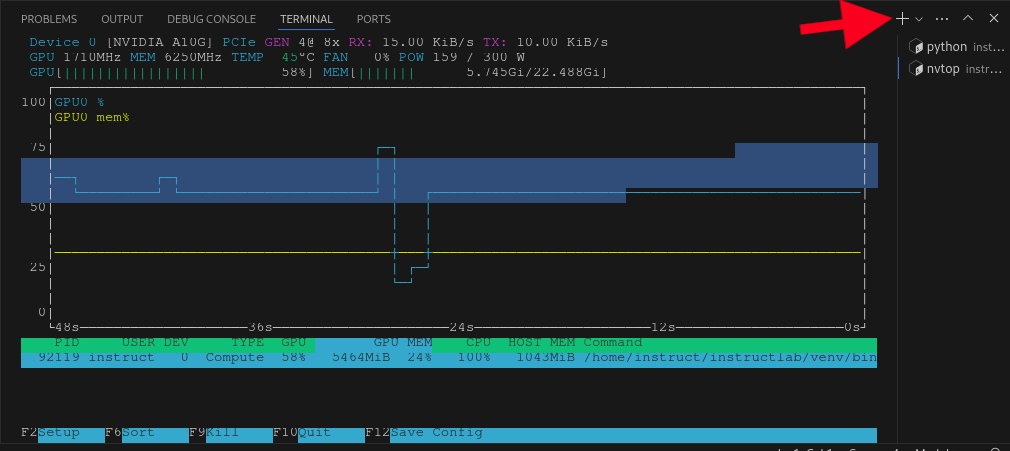
You can switch back to the original terminal by clicking on it on the right side of the screen (named python) to check on the progress of the generation.
|
If you encounter an AssertionError, this is likely due to a known issue that has been resolved in the latest InstructLab. The fix will be included in the next release. |
Once the generation stage is complete, you should see something like this:
$ ilab data generate --model ~/instructlab/models/granite-7b-lab-Q4_K_M.gguf --sdg-scale-factor 1 --enable-serving-output
Filter: 100%|████████████████████████████████████████████████| 42/42 [00:00<00:00, 2836.45 examples/s]
Filter: 100%|████████████████████████████████████████████████| 28/28 [00:00<00:00, 4355.46 examples/s]
Flattening the indices: 100%|████████████████████████████████| 22/22 [00:00<00:00, 3207.77 examples/s]
Map: 100%|███████████████████████████████████████████████████| 22/22 [00:00<00:00, 2485.04 examples/s]
Flattening the indices: 100%|████████████████████████████████| 20/20 [00:00<00:00, 2395.65 examples/s]
Casting to class labels: 100%|███████████████████████████████| 20/20 [00:00<00:00, 1306.68 examples/s]
INFO 2024-10-02 16:47:28,764 instructlab.sdg.eval_data:126: Saving MMLU Dataset /home/instruct/.local/share/instructlab/datasets/node_datasets_2024-10-02T16_21_57/mmlubench_knowledge_economy_finance_insurance_parasol.jsonl
Creating json from Arrow format: 100%|█████████████████████████████████| 1/1 [00:00<00:00, 567.10ba/s]
INFO 2024-10-02 16:47:28,780 instructlab.sdg.eval_data:130: Saving MMLU Task yaml /home/instruct/.local/share/instructlab/datasets/node_datasets_2024-10-02T16_21_57/knowledge_economy_finance_insurance_parasol_task.yaml
Map: 0%| | 0/722 [00:00<?, ? examples/s]WARNING 2024-10-02 16:47:28,802 instructlab.sdg.datamixing:223: Failed to split generated q&a: Parasol Insurance Company', founded in 1936 by James Falkner and James Labocki, is one of the largest and most well-known auto insurance companies in the United States, offering various insurance products for personal vehicles, motorcycles, homeowners, renters, boats, RVs, life insurance, business insurance, and identity theft protection. Parasol is known for its memorable advertising campaigns, user-friendly digital platforms, and competitive pricing, as well as its strong financial strength indicated by high ratings from agencies like A.M. Best.The result of this is a number of files which you can inspect in the ~/.local/share/instructlab/datasets directory. These files are used in the following training phase. Open this directory by running the following command in the Terminal:
xdg-open ~/.local/share/instructlab/datasetsyou can examine the contents of the files by double-clicking on them. For example, check out the file whose name starts with messages_granite. These are sample questions generated based on the content of our Parasol data.
5.5. Training the Model with New Data
With our synthetic data generated, we should now be in a position to train the model. Because we only created 1 sample and due to time constraints we’re not going to perform the actual training in this lab.
If we were to do this, we would again use the "ilab" CLI with the "model train" command. Something like ilab model train --device cuda. Depending on the hardware available, this can take anywhere from several minutes to several hours or days. Once this process was finished we would then have a model we can serve locally with ilab to test our results.
5.6. Serve the new Model
We have provisioned a trained model in the folder ~/instructlab/models called parasol-model.gguf. Serve this model by running the following command in the terminal:
ilab model serve --model-path ~/instructlab/models/parasol-model.ggufIt may take a minute to start, but you should see the following:
INFO instructlab.model.serve:136: Using model '/home/instruct/instructlab/models/parasol-model.gguf' with -1 gpu-layers and 4096 max context size.
INFO instructlab.model.serve:140: Serving model '/home/instruct/instructlab/models/parasol-model.gguf' with llama-cpp
INFO instructlab.model.backends.llama_cpp:232: Replacing chat template:
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ '<|user|>
' + message['content'] }}
{% elif message['role'] == 'system' %}
{{ '<|system|>
' + message['content'] }}
{% elif message['role'] == 'assistant' %}
{{ '<|assistant|>
' + message['content'] + eos_token }}
{% endif %}
{% if loop.last and add_generation_prompt %}
{{ '<|assistant|>' }}
{% endif %}
{% endfor %}
INFO instructlab.model.backends.llama_cpp:189: Starting server process, press CTRL+C to shutdown server...
INFO instructlab.model.backends.llama_cpp:190: After application startup complete see http://127.0.0.1:8000/docs for API.5.7. Interacting with the Model
To chat, open a new terminal using the + button above the terminal:
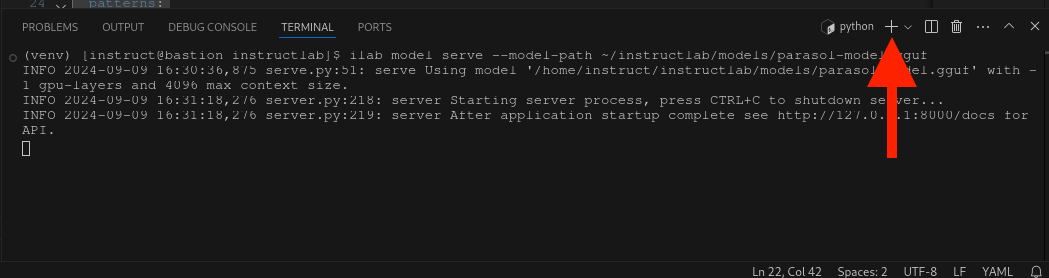
In the new terminal, run the following command to begin a chat session with the model:
cd ~/instructlab
source venv/bin/activate
ilab model chatWe can now ask the trained model some parasol specific questions such as:
-
Does Parasol insurance policies include loss of income cover if the insured driver is at fault?
-
Will Parasol insurance cover the cost of car rental if my car is undriveable as a result of an accident?
-
What is Apex plus from parasol insurance?
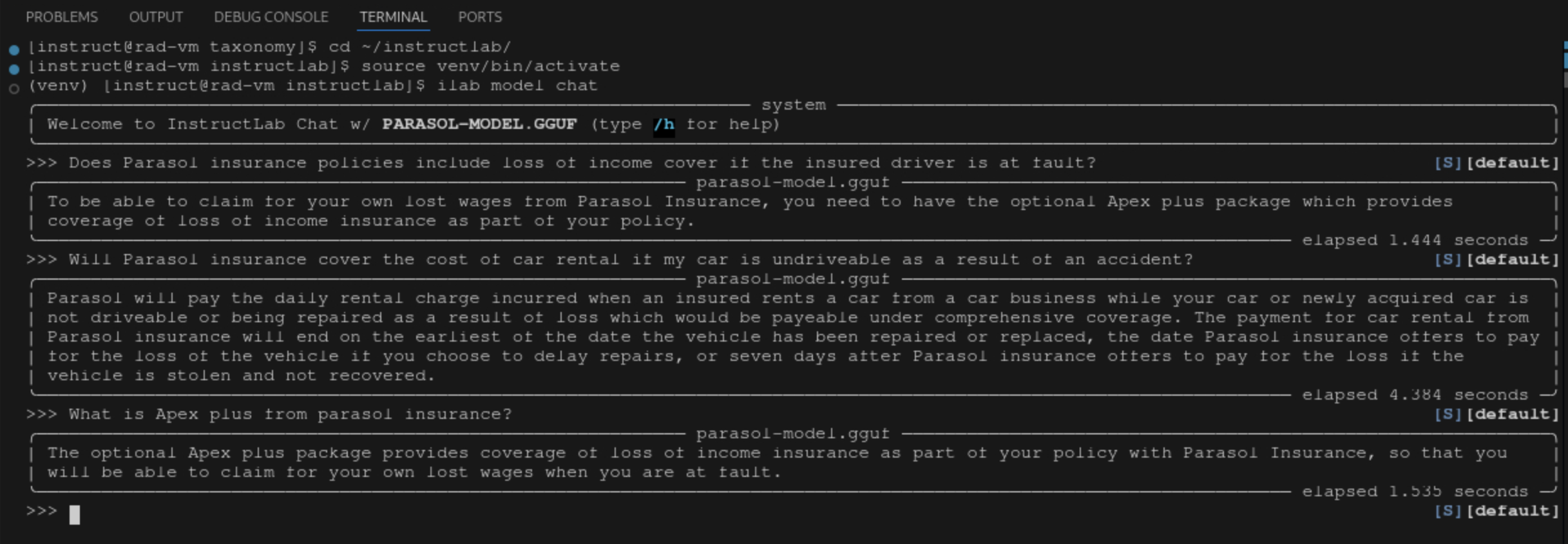
The answers are specific to Parasol’s policies and demonstrate the ability for organizations to fine-tune models with their own data, to improve the accuracy of responses, which can be used in many use cases.
5.8. Bonus: Graphical UI
In reality, Parasol employees would not be using ilab to ask the model(s) questions. For this lab, feel free to use the same application you may have seen in other exercises in this workshop. To open the application, run the following command in your Terminal:
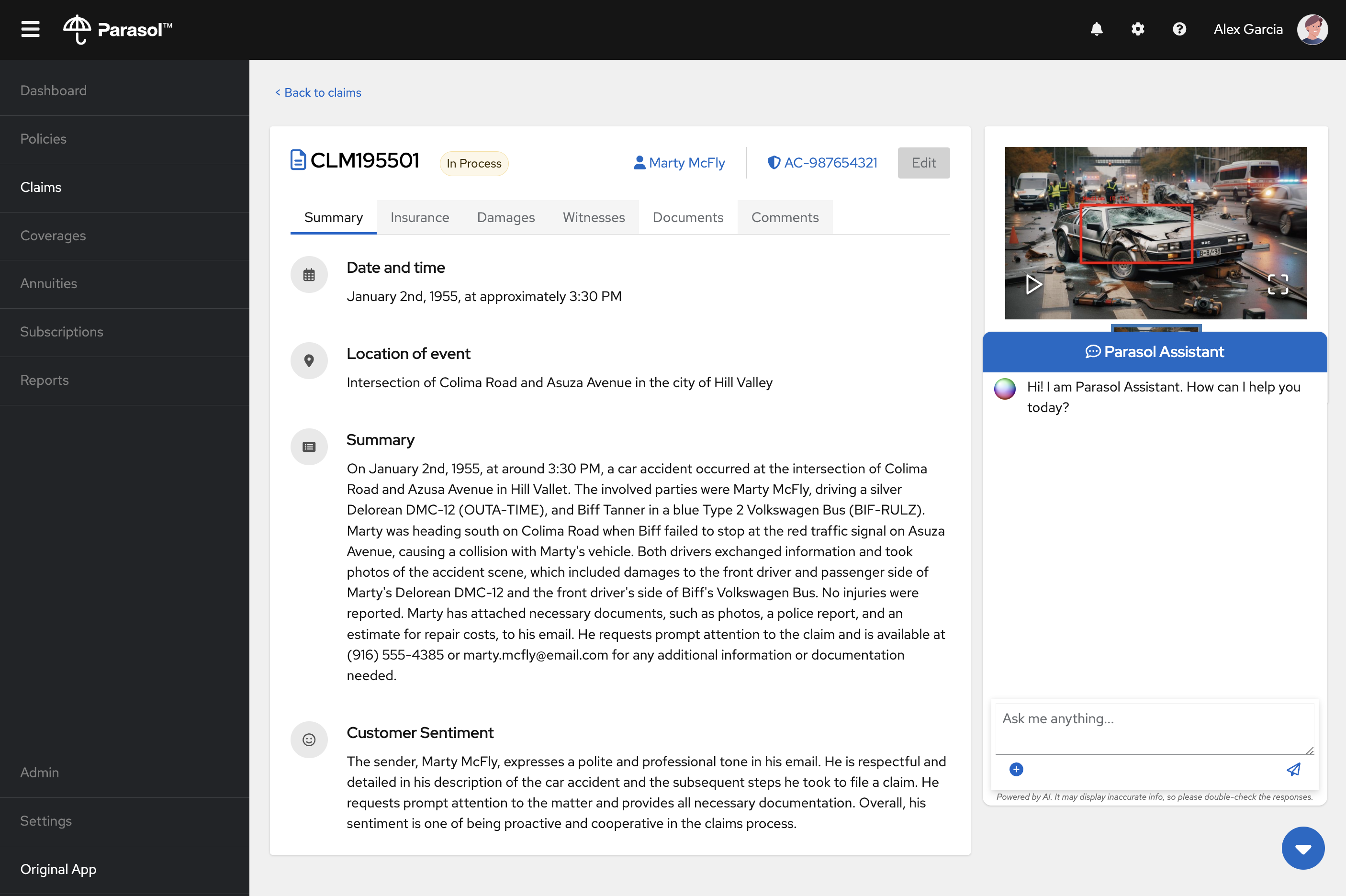
firefox http://localhost:8005This is the same Java application built on Quarkus which Parasol customer service reps use to organize claims. On the Claims page, click on the first Claim for the customer named Marty McFly.
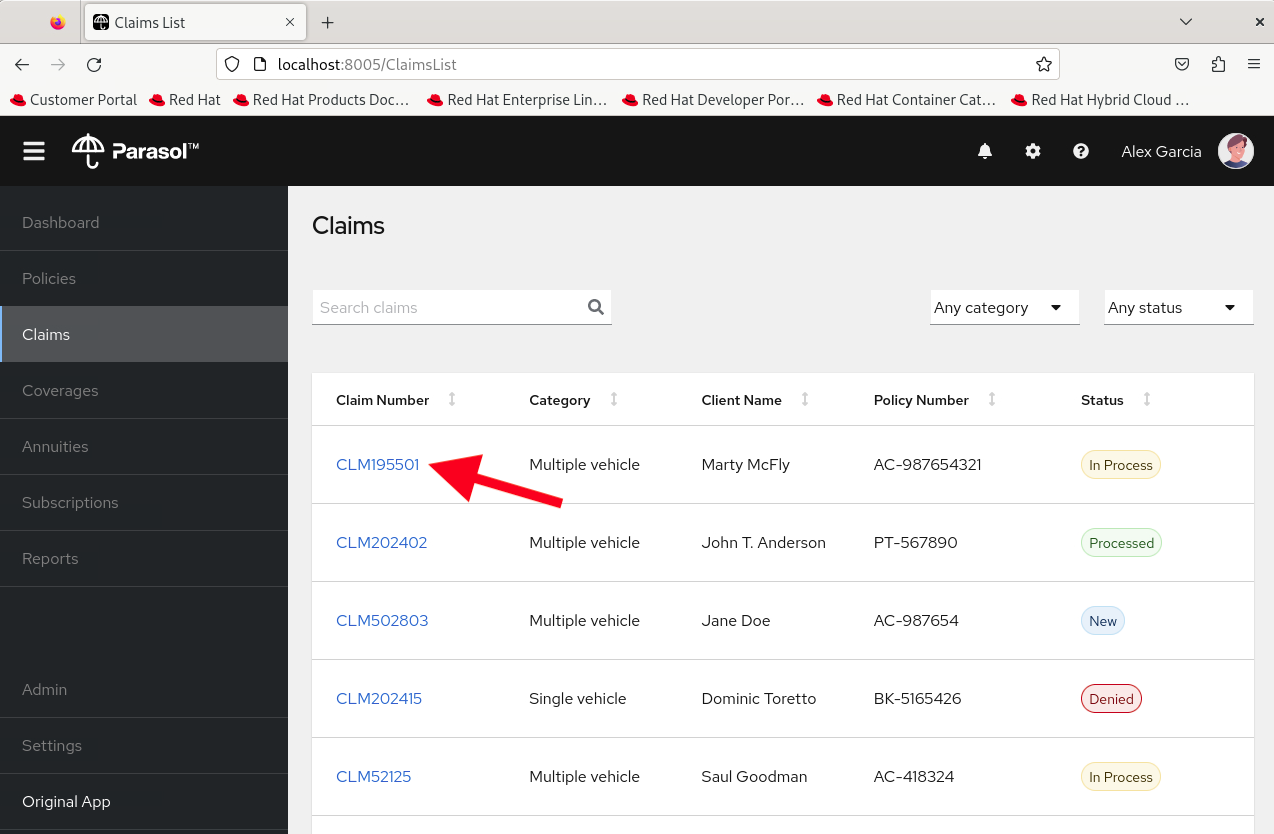
Click on the assistant chat tool at the lower right and enter the same prompts as before.
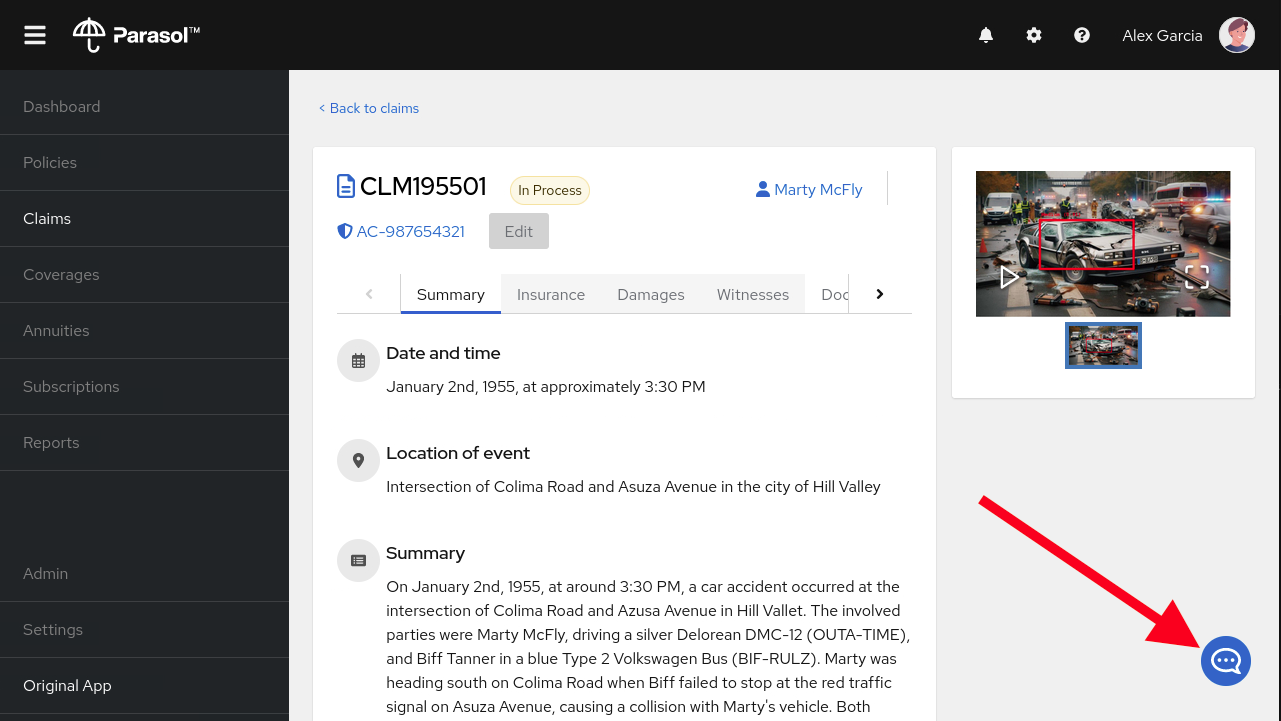
Try this one as well:
Should Parasol approve this claim?and
Who was at fault?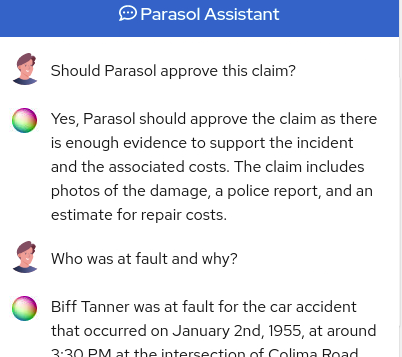
In this case, the claim information is also included in the prompt, in addition to your questions, so that the assistant can make reasonable answers based on the claim in question!
6. Conclusion
This exercise showed how organizations can leverage fine tuning with InstructLab to improve the accuracy of LLM responses. Here’s a quick summary of what we have learned:
-
You Learned about fine-tuning techniques for AI models, incorporating Parasol’s unique insurance expertise into LLMs
-
Your also learned how to create and utilize a custom knowledge base for training AI models with organization-specific scenarios and regulations
-
Apply the LAB methodology to generate synthetic training data and specialize our model while keeping data in-house
-
You gained hands-on experience in training and serving a customized AI model
-
You understand the benefits and limitations of fine-tuning compared to other AI customization methods
These skills and tools will be invaluable as you continue to develop AI-enabled applications at Parasol Insurance, allowing you to quickly iterate on ideas and integrate powerful AI capabilities into your workflow.